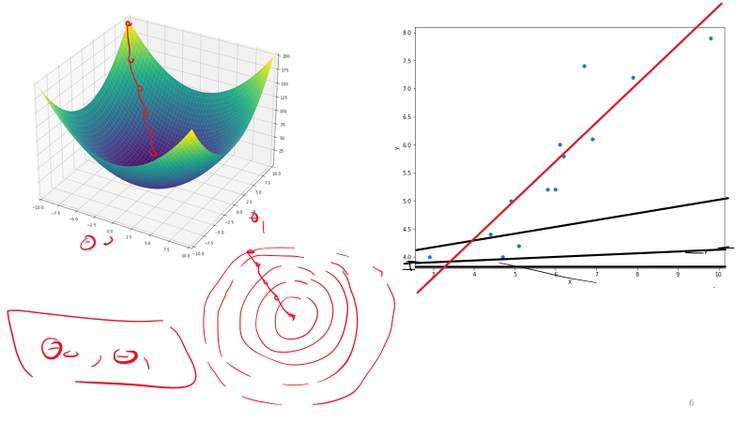
Machine Learning and Deep Learning Optimizers Implementation

- Description
- Curriculum
- FAQ
- Reviews
In this course you will learn:
1- How to implement batch (vanilla) gradient descent (GD) optimizer to obtain the optimal model parameters of the single and Multi variable linear regression (LR) models.
2- How to implement mini-batch and stochastic GD for single and multi-variable LR models.
You will do this by following the guided steps represented in the attached notebook.
In addition a video series describing each step.
You will also implement the cost function, stop conditions, as well as plotting the learning curves.
You will understand the power of applying vectorize implementation of the optimizer.
This implementation will help you to solidify the concept and gain the momentum of how the optimizers work during training phase.
By the end of this course you will obtain the balance between the theoretical and practical point of view of the optimizers that is used widely in both machine learning (ML) and deep learning (DL).
In this course we will focus on the main numerical optimization concepts and techniques used in ML and DL.
Although, we apply these techniques for single and multivariable LR, the concept is the same for other ML and DL models.
We use LR here for simplification and to focus on the optimizers rather than the models.
In the subsequent practical works we will scale this vision to implement more advanced optimizers such as:
– Momentum based GD.
– Nestrov accelerated gradient NAG.
– Adaptive gradient Adagrad.
– RmsProp.
– Adam.
– BFGS.
You will be provided by the following:
– Master numerical optimization for machine learning and deep learning in 5 days course material (slides).
– Notebooks of the guided steps you should follow.
– Notebooks of the practical works ideal solution (the implementation).
– Data files.
You should do the implementation by yourself and compare your code to the practical session solution provided in a separate notebook.
A video series explaining the solution is provided. However, do not see the solution unless you finish your own implementation.
-
8
 About the Lab
About the Lab -
9
Regression Data
-
10
Model Parameters Initialization
-
11
Model Prediction
-
12
Cost Calculation
-
13
Gradient Calculation
-
14
Model Parameters Update
-
15
Iterate Till Achieving the Optimum Parameter Values
-
16
Optimizer Output
-
17
Gradient Stop Condition
-
18
Gradient Stop Condition Output
-
19
Model Performance Evaluation
-
20
How to Obtain Better Model Performance?
-
21
Plotting of Learning Curves
-
22
Loss vs Epochs
-
23
Loss vs Model Parameters
-
24
Interpretation Loss vs Epochs
-
25
Interpretation Loss vs Model Parameters
-
26
Cost Convergence Check
-
28
Step by Step Implementation
-
29
Iterate Till Achieving the Optimum Parameter Values
-
30
Gradient Stop Condition
-
31
Model Performance Evaluation
-
32
Different Hyperparameter Combinations
-
33
Plotting Loss vs. Epochs
-
34
Plot Loss vs Model Parameters
-
35
Cost Convergence Check
-
36
Make Your Implementation as a Function.
-
37
Using Your Function to Explore Learning Rate Effect
-
39
Reminder of Single Variable LR Optimization
-
40
Multivariable LR Optimization Problem Definition
-
41
Multivariable LR Optimization Problem Solution Using Vectorize Implementation_1
-
42
Multivariable LR Optimization Problem Solution Using Vectorize Implementation_2
-
43
Vectorize Implementation_3 Gradient Vector Calculation
-
44
Multivariable LR Optimization Problem Solution Using Vectorize Implementation_4
-
45
Vectorize Implementation_5 Generalized Implementation for Single and Multivar LR
-
54
Data Preparation
-
55
Step by Step Implementation
-
56
Putting All Steps Togeteher
-
57
Results and Model Evaluation
-
58
Learning Curves_1 Loss vs. Epochs
-
59
Learning Curves_2 Loss vs. Model Parameters (Thetas)
-
60
Different Scenarios With Different Hyperparameters
-
61
Multivariable LR Optimization Implementation as a Function
-
62
Introduction
-
63
The main idea_1_Epoch vs. iteration
-
64
The main idea_2_Batch GD problems
-
65
The main idea_3_Stochastic GD (SGD)
-
66
Implementation steps 1 (Tips and Tricks)
-
67
Implementation steps 2 (Data generation and applying batch GD)
-
68
Implementation steps 3 (step by step)
-
69
Implementation steps 4 (Iterate to finish one epoch)
-
70
Implementation steps 5 (more epochs and stop condition tricks)
-
71
Implementation steps 6 (results and discussion)
-
72
Data Generation
-
73
Batch GD Scenario
-
74
Implementation steps 1 (Data Shuffle)
-
75
Implementation steps 2 (One iteration)
-
76
Implementation steps 3 (Iterate to finish one epoch)
-
77
Implementation steps 4 (More epochs)
-
78
Learning curves and model evaluation
-
79
SGD for single variable LR as a function
-
80
SGD vs. batch GD using different hyperparameters